- 图的定义:图(Graph)是由顶点(Vertex)和边(Edge)组成的数学结构具体概念见图的论述.
- 图的存储
- 邻接矩阵:图的邻接矩阵是一种用于表示图的存储结构,其中矩阵的行数和列数都对应于图的顶点,矩阵的元素表示顶点之间的边。在邻接矩阵中,如果顶点i与顶点j之间存在边,则矩阵的第i行第j列(记作aij)处的元素为1(或边的权重),否则为0。
- 邻接表:邻接表是图的一种存储方式,用于表示图中的顶点之间的连接关系。在邻接表中,每个顶点都有一个列表,该列表包含了与该顶点直接相连的所有顶点。
- 十字链表:十字链表是一种存储无向图或正则图的数据结构,它将图中每个顶点的邻接顶点按照字典序排列,并存储到两个列表中,分别称为该顶点的出度和入度列表。
- 邻接多重表:邻接多重表是一种表示无向图或有权图的的数据结构。在这种数据结构中,每个顶点都有一个表,这个表记录了与该顶点相邻的所有顶点以及相邻的边。
- 图的基本操作
public class GraphDemo { private Map<String, List<String>> graph; public GraphDemo() { graph=new HashMap<>(); } //添加节点 public void addVertices(String name){ graph.put(name,new ArrayList<>()); } //添加边 public void addEdge(String startName,String endName){ if (graph.containsKey(startName)&&graph.containsKey(endName)){ graph.get(startName).add(endName); }else { throw new RuntimeException("节点不存在"); } } //删除节点 public void removeVertex(String name){ if (graph.containsKey(name)){ List<String> neighbors = graph.get(name); for (String neighbor : neighbors) { graph.get(neighbor).remove(name); } graph.remove(name); } } //删除边 public void removeEdge(String startName,String endName){ if (graph.containsKey(startName)&&graph.containsKey(endName)){ graph.get(startName).remove(endName); graph.get(endName).remove(startName); } } } - 图的遍历
- 深度优先搜索(DFS):图的深度优先遍历(Depth-First Traversal)是一种用于遍历图的算法,它沿着一条路径尽可能深入,直到达到最深的顶点,然后回溯,再沿着另一条路径深入。这种算法适用于发现图中环、连通分量等性质,由于每个顶点和每条边都会被访问一次,所以时间复杂度是O(V+E)。。
public void dfs(String startName){ //创建栈 Stack<String> stack = new Stack<>(); stack.push(startName); while (!stack.isEmpty()){ String vertex = stack.pop(); System.out.println(vertex+" "); List<String> neighbors = graph.get(vertex); //遍历邻居节点 for (String neighbor:neighbors){ if (!stack.contains(neighbor)){ stack.push(neighbor); } } } } - 广度优先搜索(BFS):广度优先搜索(Breadth-First Search,BFS)是一种用于图遍历或搜索的算法。与深度优先搜索(DFS)沿着一条路径尽可能深入不同,BFS采取一步一个顶点的方式进行搜索,即在每一层尽可能扩散得广,这段代码的时间复杂度是 O(V+E),其中 V 是顶点的数量,E 是边的数量。。
public void bfs(String statName){ Queue<String> queue = new LinkedList<>(); queue.offer(statName); while (!queue.isEmpty()){ String vetex = queue.poll(); System.out.println(vetex+""); List<String> neighbors = graph.get(vetex); for (String neighbor:neighbors){ if (!queue.contains(neighbor)){ queue.add(neighbor); } } } } - 深度优先搜索的主要应用场景
- 路径寻找:DFS 可以用来寻找从一个顶点到另一个顶点的路径。
- 连通分量:DFS 可以用来找到图中的连通分量,即无法通过任何边连接的顶点集合。
- 环检测:DFS 可以用来检测图中是否存在环。
- 拓扑排序:DFS 可以用来进行拓扑排序,即对有向图进行顶点排序,使得对于任何一条边 (u, v),都满足 u 在 v 之前。
- 广度优先搜索的主要应用场景
- 寻找最短路径:BFS 可以用来寻找从源顶点到其他所有顶点的最短路径。
- 查找特定距离的顶点:BFS 可以用来查找与源顶点距离为 k 的所有顶点。
- 连通分量:BFS 可以用来找到图中的连通分量,与 DFS 类似,但 BFS 更适合处理较大的连通分量。
- 网络延迟:BFS 可以用来计算网络延迟,即从源顶点到其他所有顶点的最短延迟。
- 深度优先搜索(DFS):图的深度优先遍历(Depth-First Traversal)是一种用于遍历图的算法,它沿着一条路径尽可能深入,直到达到最深的顶点,然后回溯,再沿着另一条路径深入。这种算法适用于发现图中环、连通分量等性质,由于每个顶点和每条边都会被访问一次,所以时间复杂度是O(V+E)。。
- 图的应用
- 最小生成树:最小生成树(Minimum Spanning Tree,MST)是一棵包含图所有顶点的树形结构,并且它的边权之和尽可能小。这里的边权是指图中每条边的权重,权重越小说明树的边越短,树的高度也越小,从而整个树的路径长度也越小。
求最小生成树的问题通常可以通过以下几种算法解决:- 普里姆算法(Prim algorithm):普里姆算法(Prim’s algorithm)是一种用于寻找加权无向图最小生成树的算法。最小生成树是一组边,它们连接了图中的所有顶点,且树中所有边的权值之和最小。
以下是使用普里姆算法找到最小生成树的步骤:- 创建一个包含所有顶点的集合,以及一个空的最小生成树集合。
- 从任意顶点开始,将其加入最小生成树集合中,并将其从所有顶点的集合中移除。
- 找到与当前最小生成树集合中顶点相邻的顶点中权值最小的顶点,将其加入最小生成树集合中,并将其从所有顶点的集合中移除。
- 重复步骤 3,直到所有顶点都被加入最小生成树集合中。
- 克鲁斯卡尔算法(Kruskal algorithm):克鲁斯卡尔(Kruskal)算法是一种用来寻找最小生成树的算法。最小生成树是一棵包含图中所有顶点的树形结构,并且其边的权重之和尽可能小。
克鲁斯卡尔算法的步骤如下:- 将所有顶点构成若干个互不相交的子集,即每个顶点都是一个独立的连通分量。
- 将所有边按权重从小到大排序。
- 遍历排序后的边,对于每一条边,如果这条边连接的两个顶点属于不同的连通分量,则将这条边加入到最小生成树中,然后将这两个连通分量合并。
- 重复步骤 3,直到所有顶点都属于同一个连通分量。
- 此时,图中最小的生成树已经找齐。
- 算法比较
普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法在实现的所不同:- 普里姆算法是一种贪心算法,其基本思想是:从一个顶点开始,每次选择与当前连通分量边界上权最小的边,将其加入连通分量中,并更新边界。这个过程会一直进行,直到所有顶点都被包含在连通分量中。克鲁斯卡尔算法是一种基于排序的算法。它首先将所有边按权重从小到大排序,然后遍历排序后的边,对于每一条边,如果这条边连接的两个顶点属于不同的连通分量,则将这条边加入到最小生成树中,然后将这两个连通分量合并。这个过程会一直进行,直到所有顶点都属于同一个连通分量。
- 数据结构:普里姆算法使用一个优先队列(最小堆)来存储待处理的边,而克鲁斯卡尔算法使用一个已排序的边列表。
- 时间复杂度:普里姆算法的时间复杂度是 O(V^2),其中 V 是顶点的数量。克鲁斯卡尔算法的时间复杂度是 O(ElogE),其中 E 是边的数量。在边数量较多时,克鲁斯卡尔算法通常比普里姆算法更快。
- 空间复杂度:普里姆算法需要维护一个优先队列,因此其空间复杂度与顶点数量成正比。克鲁斯卡尔算法需要维护一个已排序的边列表,因此其空间复杂度与边数量成正比。
- 适用性:普里姆算法适用于稠密图,因为其时间复杂度较低。克鲁斯卡尔算法适用于稀疏图,因为其时间复杂度较高。
- 应用场景:最小生成树(Minimum Spanning Tree,MST)在许多实际场景中都有广泛应用,以下是一些常见的应用场景:
- 通信网络设计:在构建通信网络时,需要确保所有节点之间都能互相通信,同时 minimize 总花费(例如,购买光纤、微波塔等)。
- 路由表优化:在路由器中,最小生成树可以用于优化路由表,从而提高数据传输效率。
- 图像处理:在图像处理中,最小生成树可以用于图像压缩、图像分割等任务。
- 普里姆算法(Prim algorithm):普里姆算法(Prim’s algorithm)是一种用于寻找加权无向图最小生成树的算法。最小生成树是一组边,它们连接了图中的所有顶点,且树中所有边的权值之和最小。
- 最短路径:最短路径问题是指在带权重的图中寻找从起点到终点的最短路径。在这个问题中,权重通常表示两点之间的距离或花费。
- Dijkstra 算法:Dijkstra 算法是一种用于计算图中顶点之间最短路径的算法。它不适用于有负权边的图。算法步骤如下:
- 初始化距离数组 dist,将起点到其他所有顶点的距离设为无穷大,将起点到自身的距离设为 0。
- 创建一个优先队列(最小堆),将所有顶点及其距离放入队列。
- 当队列不为空时,取出队列中距离起点最近的顶点,并将其从队列中移除。
- 遍历当前顶点的所有邻接顶点,计算从起点到邻接顶点的距离,如果该距离小于已知的最短距离,则更新最短距离,并将该邻接顶点压入队列。
- 重复步骤 3 和 4,直到队列为空。
- Floyd-Warshall 算法是一种用于计算图中所有顶点之间最短路径的算法。它适用于有负权边的图。以下是 Floyd-Warshall 算法的步骤:
- 初始化距离矩阵 dist,将图中所有顶点之间的距离初始化为无穷大,将起点到其他所有顶点的距离设为有向边或无向边的权值,节点到自己的距离为0。
- 以三个顶点的有向图为例,先将V[0]作为中间结点若dist[i][j]的值大于dist[i][0]+dist[0][j]则更新dist[i][j]的值.
- 以此类推直到所有的节点都遍历一遍.
- 算法比较
- 复杂度:Dijkstra 算法的复杂度为 O(V^2),而 Floyd-Warshall 算法的复杂度为 O(V^3)。
- 更新最短路径的方式:在 Dijkstra 算法中,我们通过比较顶点的距离值来更新最短路径;在 Floyd-Warshall 算法中,我们通过遍历所有顶点来更新最短路径。
- 算法实现方式:Dijkstra 算法使用优先队列(最小堆)来存储待处理的顶点,而 Floyd-Warshall 算法使用二维距离矩阵来存储顶点之间的最短距离。
- 适用性:Dijkstra 算法不适用于有负权边的图,而 Floyd-Warshall 算法适用于有负权边的图。
- 应用场景
- 文件传输:在文件传输过程中,需要计算两点之间的最短路径,以便选择最优的传输路径,以提高传输速度和减少传输成本。
- 网络通信:在网络通信中,需要计算两点之间的最短路径,以便数据包能够以最短的时间从源节点到达目标节点。
- 算法研究:最短路径问题是一种重要的算法问题,是许多算法研究的基础。在计算机上,可以进行最短路径算法的模拟和优化研究。
- 游戏设计:在游戏设计中,最短路径问题可以用于计算角色移动的最短路径,以便设计更合理的游戏关卡和路径。
- 人工智能:在人工智能中,最短路径问题可以用于计算机器人移动的最短路径,以便实现机器人的自主导航和路径规划。
- Dijkstra 算法:Dijkstra 算法是一种用于计算图中顶点之间最短路径的算法。它不适用于有负权边的图。算法步骤如下:
- 拓扑排序
- 什么是AOV网:AOV(Activity On Vertex)网是一种用顶点表示活动,用边表示活动之间依赖关系的网络。它主要用于表示工程中的任务及其依赖关系,以便进行项目计划和进度控制。在 AOV 网中,每个顶点表示一个活动,每条边表示两个活动之间的依赖关系。例如,活动 A 在活动 B 之前完成,那么在 AOV 网中,从顶点 A 到顶点 B 有一条有向边。
- 什么是拓扑排序:拓扑排序是对有向无环图的顶点的一种排序,他使得若只存在一条从a到b的路径,那排序中b出现在a的后面.
- 对aov网排序的步骤
- 初始化一个队列,用于存储待处理的顶点。
- 遍历图中的所有顶点,将入度为0的顶点加入队列。
- 当队列不为空时,取出队列中的顶点,并将其从图中删除。然后,遍历该顶点的所有邻接顶点,将它们的入度减1。如果减1后入度为0,则将该邻接顶点加入队列。
- 重复步骤3,直到队列为空。
- 应用场景:
- 项目计划和进度控制:在项目管理中,可以使用拓扑排序来确定任务的优先级,以便按照合理的顺序完成任务。
- 网络通信:在网络通信中,可以使用拓扑排序来确定数据包的传输顺序,以便按照合理的路径传输数据。
- 算法研究:拓扑排序是一种重要的算法问题,是许多算法研究的基础。在计算机科学领域,可以进行拓扑排序的模拟和优化研究。
- 游戏设计:在游戏设计中,可以使用拓扑排序来确定角色移动的顺序,以便设计更合理的游戏关卡和路径。
- 判断无环图
- 判断无环图的过程:
- 从一个节点出发,遍历所有周围节点,将遍历过的节点加入visited数组和stack栈中
- 每次遍历都是将节点和节点的临近节点以此递归下去进行遍历,同时加入stack栈中,若栈在某次递归中包含了某个节点,说明形成了一个闭环,则直接返回false
- 否则当所有的临近节点都访问过后将stack栈清楚.
- 返回到过程a(因为可能存在其他联通分量)
//DFS判断无环图 public boolean dfs(String vetex,Map<String,Boolean> visited,Map<String,Boolean> stack){ //判断是否包含在栈中 if (stack.containsKey(vetex)){ return true; } //判断是否被访问过 if (visited.containsKey(vetex)){ return false; } visited.put(vetex,true); stack.put(vetex,true); for (String neighbor:graph.get(vetex)){ if (dfs(neighbor,visited,stack)){ return true; } } stack.remove(vetex); return false; } public boolean hasCycle(){ //创建记录对象 HashMap<String,Boolean> visited = new HashMap<>(); //遍历所有节点 for (String vetex:graph.keySet()){ //如果节点未被访问过 if (!visited.containsKey(vetex)){ if (dfs(vetex,visited,new HashMap<>())){ return true; } } } return false; }
- 判断无环图的过程:
//BFS判断无环图 public boolean bfs(String vertex,Map<String,Boolean> visites,Queue<String> queue){ visites.put(vertex,true); queue.add(vertex); while (!queue.isEmpty()){ String current=queue.poll(); for (String neighbor:graph.get(current)){ //若没访问过 if (!visites.containsKey(neighbor)){ visites.put(neighbor,true); queue.add(neighbor); //已经访问过 }else { return true; } } } return false; } public boolean hasCycle2(){ HashMap<String,Boolean> visited = new HashMap<>(); Queue<String> queue = new LinkedList<>(); for (String vertex:graph.keySet()){ if (!visited.containsKey(vertex)){ if (bfs(vertex,visited,queue)){ return true; } } } return false; }- 关键路径
- AOE网:AOE(Activity On Edge)网是一种用于表示活动及其依赖关系的图。它通过边表示活动,通过顶点表示活动之间的依赖关系。AOV网的边无权值,AOE网的边有权值.
- 关键路径,关键活动:把具有最大路径长度的路径称为关键路径,而把关键路径上的活动称为关键活动.
- 最小生成树:最小生成树(Minimum Spanning Tree,MST)是一棵包含图所有顶点的树形结构,并且它的边权之和尽可能小。这里的边权是指图中每条边的权重,权重越小说明树的边越短,树的高度也越小,从而整个树的路径长度也越小。
- 图的实际应用场景
- 社交网络:图可以用来表示社交网络中的用户及其之间的关系。例如,Facebook 使用图结构来存储用户及其好友之间的关系,以便快速推荐可能认识的人、找到共同好友等。
- 推荐系统:图可以用来表示用户与物品之间的交互关系,例如用户购买商品、给商品打分等。通过分析这些关系,可以构建推荐系统,为用户提供个性化的推荐。
- 地图导航:图可以用来表示地图上的道路网络,节点表示道路交叉点,边表示道路连接。通过使用图数据结构,可以实现地图导航功能,例如计算最短路径、推荐路线等。
- 知识图谱:图可以用来表示实体(如人物、地点、组织等)及其之间的关系。例如,Google 的 Knowledge Graph 就是一个大规模的知识图谱,用于提供关于实体及其关系的详细信息。
- 机器学习:图在机器学习中用于表示数据集中的对象及其之间的关系。例如,图神经网络(GNN)是一种针对图数据的深度学习模型,可以用于学习图上的特征,并用于预测和分类。
数据结构-图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mfbz.cn/a/559489.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈qq邮箱809451989@qq.com,一经查实,立即删除!相关文章

数字乡村创新实践推动农业现代化发展:科技赋能农业产业升级、提升农民收入水平与乡村治理效能
随着信息技术的迅猛发展和数字化转型的深入推进,数字乡村创新实践已成为推动农业现代化发展的重要引擎。数字技术的广泛应用不仅提升了农业生产的智能化水平,也带动了农民收入的增加和乡村治理的现代化。本文旨在探讨数字乡村创新实践如何科技赋能农业产…

Ubuntu24.04之软件源修改
注意事项
Ubuntu24.04的软件源从/etc/apt/sources.list改为/etc/apt/sources.list.d/ubuntu.sources
修改步骤
#备份软件源
sudo cp /etc/apt/sources.list.d/ubuntu.sources /etc/apt/sources.list.d/ubuntu.sources.bak
#更换软件源(更换为中科大源࿰…
使用 CentOS 搭建 Linux KVM 虚拟化平台
(1)上传镜像,可在这个链接上下载镜像:https://mirrors.aliyun.com/centos-vault/7.7.1908/isos/x86_64/CentOS-7-x86_64-Minimal-1908.iso?spma2c6h.25603864.0.0.4a41714fA9E9c0 (2). 在 CentOS 图形界面打开虚拟系统…
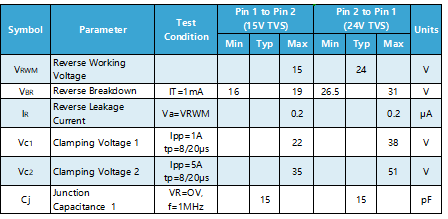
LIN数据总线ESD保护方案
LIN总线(Local Interconnect Network)是一种用于车辆电子系统中的串行通信协议。LIN接口与其他外露的接口一样,也会受到静电放电 (ESD) 的影响。电子工程师需设计具有保护二极管的LIN 接口可为 LIN 收发器本身和相应的下游总线元件提供保护。…
【源码】基于I.MX6ull驱动移植ds18b20的实验详解
文章目录 前言一、硬件连接二、代码移植1.驱动代码2.编译程序 三、移植到开发板参考连接 前言
提示:基于I.MX6ull驱动移植ds18b20的实验:
实验平台:正点原子alpha开发板V2.2 传感器:ds18b20模块 一、硬件连接
ds18b20的VCC&…

在瑞芯微RV1126 Linux系统上调试WiFi的详细指南
目录标题 1. **系统和环境准备**2. **检查WiFi设备状态**3. **启用和禁用WiFi接口**4. **扫描可用的WiFi网络**5. **连接到WiFi网络**6. **查看当前的WiFi连接状态**7. **断开和重新连接WiFi**8. **管理WiFi网络配置**9. **使用iw工具进行高级WiFi调试**10. **故障排除和日志获…

Kafka安装Windows版
系列文章目录 文章目录 系列文章目录前言前言
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。 Kafka 是一个由 LinkedIn 开发的分布式消息系统,它于2011年年初开源,现…
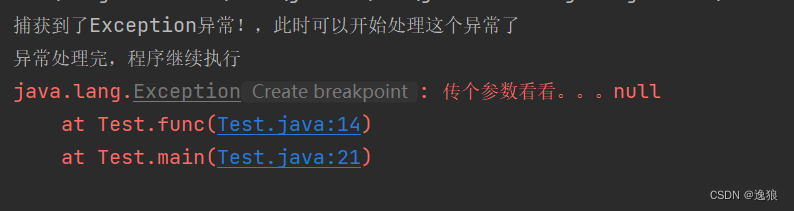
【JavaSE】异常
欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎指出~ 目录 认识异常 异常分类 举例 栈溢出错误 空指针异常(运行时异常) 编译时异常 处理异常 抛出 异常 程序本身触发异常 手动抛出异常 举例 利用try ca…

【MATLAB】App 设计 (入门)
设计APP 主界面 函数方法
定时器
classdef MemoryMonitorAppExample < matlab.apps.AppBase% Properties that correspond to app componentsproperties (Access public)UIFigure matlab.ui.FigureStopButton matlab.ui.control.ButtonStartButton matlab.ui.cont…

openAI tts Java文本转语音完整前后端代码 html
Java后端代码
maven 仓库:
<!--openAI 请求工具-->
<dependency><groupId>com.unfbx</groupId><artifactId>chatgpt-java</artifactId><version>1.1.5</version>
</dependency>maven 仓库官方 tts 使用案例…

【论文源码实战】轻量化MobileSAM,分割一切大模型出现,模型缩小60倍,速度提高40倍
前言
MobileSAM模型是在2023年发布的,其对之前的SAM分割一切大模型进行了轻量化的优化处理,模型整体体积缩小了60倍,运行速度提高40倍,但分割效果却依旧很好。
MobileSAM在使用方法上沿用了SAM模型的接口,因此可以与…
超越GPT-4V,苹果多模态大模型上新,神经形态计算加速MLLM(一)
4月8日,苹果发布了其最新的多模态大语言模型(MLLM )——Ferret-UI,能够更有效地理解和与屏幕信息进行交互,在所有基本UI任务上都超过了GPT-4V!
苹果开发的多模态模型Ferret-UI增强了对屏幕的理解和交互&am…
![【YOLOv8改进[Backbone]】使用MobileNetV3助力YOLOv8网络结构轻量化并助力涨点](https://img-blog.csdnimg.cn/direct/f4e46c4ccc8d4252ba4ba71cb80d1551.png)
【YOLOv8改进[Backbone]】使用MobileNetV3助力YOLOv8网络结构轻量化并助力涨点
目录
一 MobileNetV3
1 面向块搜索的平台感知NAS和NetAdapt
2 反向残差和线性瓶颈
二 使用MobileNetV3助力YOLOv8
1 整体修改
① 添加MobileNetV3.py文件
② 修改ultralytics/nn/tasks.py文件
③ 修改ultralytics/utils/torch_utils.py文件
2 配置文件
3 训练
其他 …

内置管线升级到SBP,如何复用之前打包的AssetBundle
1)内置管线升级到SBP,如何复用之前打包的AssetBundle 2)安卓真机,在Unity 2021.3.31版本下Buffer数据异常 3)URP里CullResults.CreateSharedRendererScene下面的消耗 4)移动端是否支持曲面细分着色 这是第3…

C#基础|Debug程序调试学习和技巧总结
哈喽,你好啊,我是雷工!
在程序的开发过程中,可能绝大部分时间是用来调试程序, 当完成了某个功能的编程,都需要调试一下程序,看编程是否存在问题。
01 为什么需要程序调试
无论是电气工程师还…
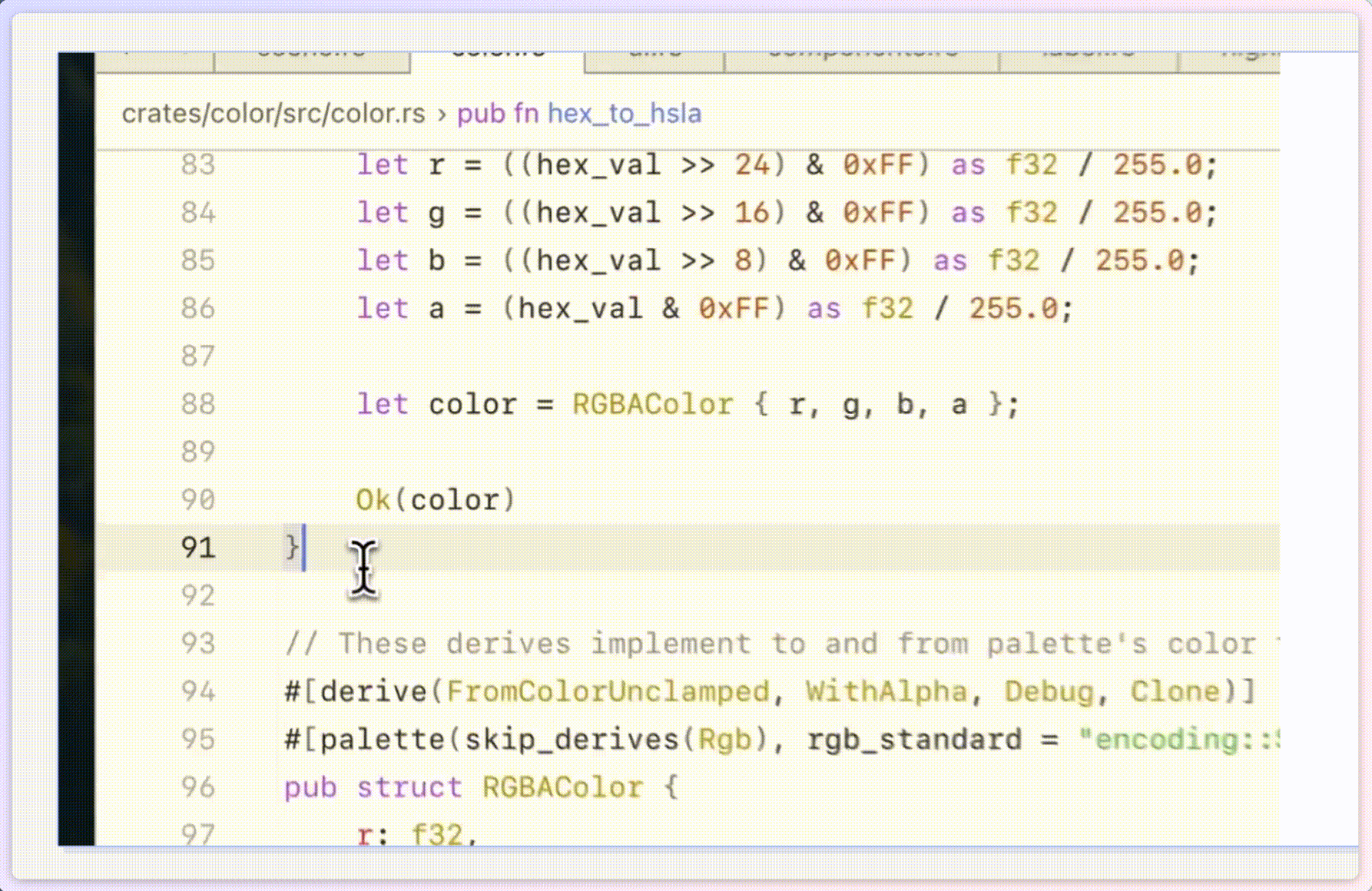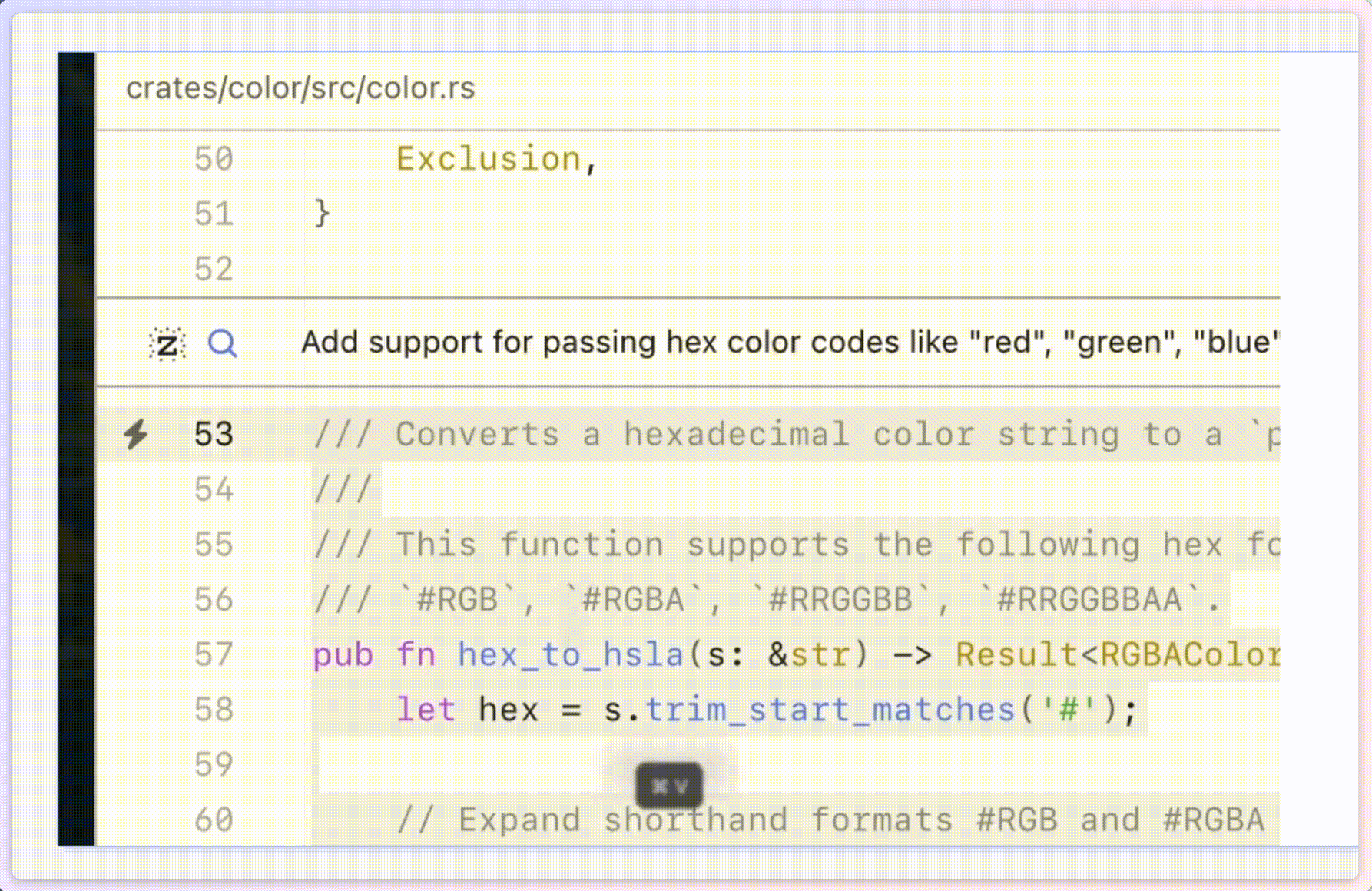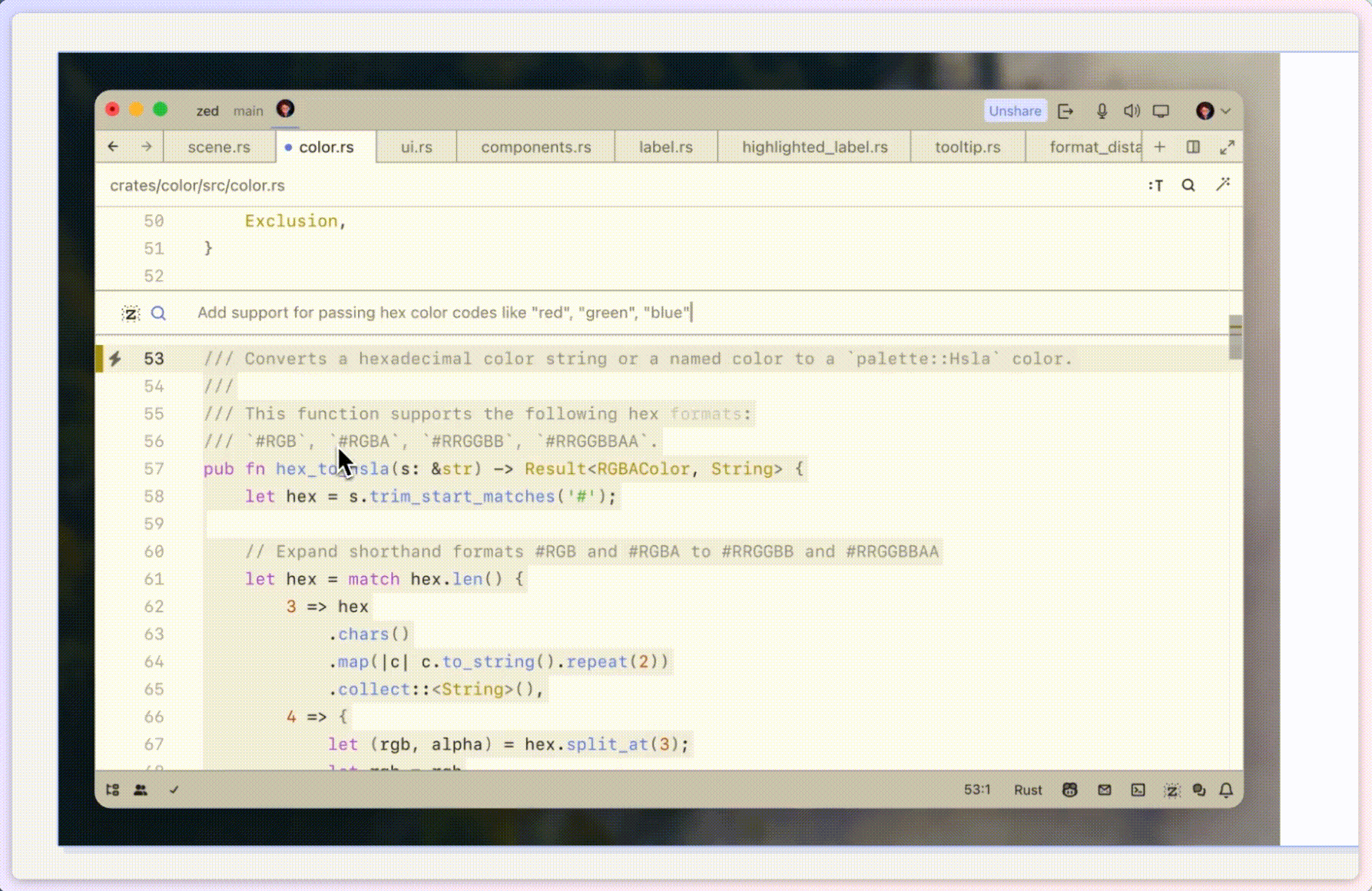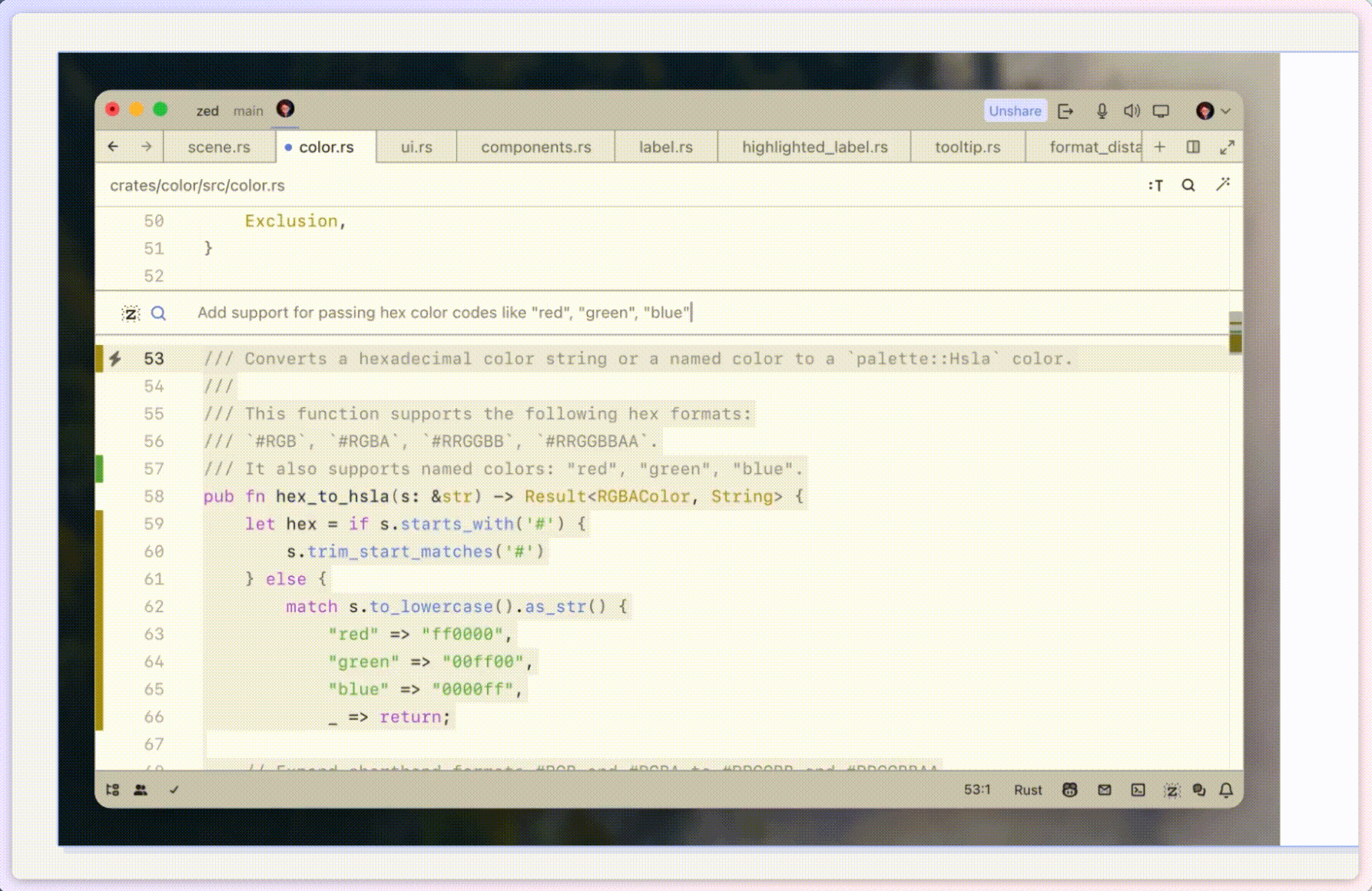
Zed,有望打败 VS Code 吗?
大家好,我是楷鹏。
先说结论,不行。
Zed,又一款新起的文本代码编辑器 👉 https://zed.dev 今年一月二十四号正式开源,短短不到三个月,GitHub 上已经冲上 3 万 star 正如 Zed 的口号所说「Code at the spe…

win11家庭中文版安装docker遇到Hyper-V启用失败,如何解决??
🏆本文收录于「Bug调优」专栏,主要记录项目实战过程中的Bug之前因后果及提供真实有效的解决方案,希望能够助你一臂之力,帮你早日登顶实现财富自由🚀;同时,欢迎大家关注&&收藏&&…
统一所有 LLM API:支持预算与速率限制 | 开源日报 No.229
BerriAI/litellm
Stars: 6.7k License: NOASSERTION litellm 是一个使用 OpenAI 格式调用所有 LLM API 的工具。它支持 Bedrock、Azure、OpenAI、Cohere、Anthropic 等 100 多种 LLMs,提供企业级代理服务器和稳定版本 v1.30.2。 主要功能和优势包括:
将…
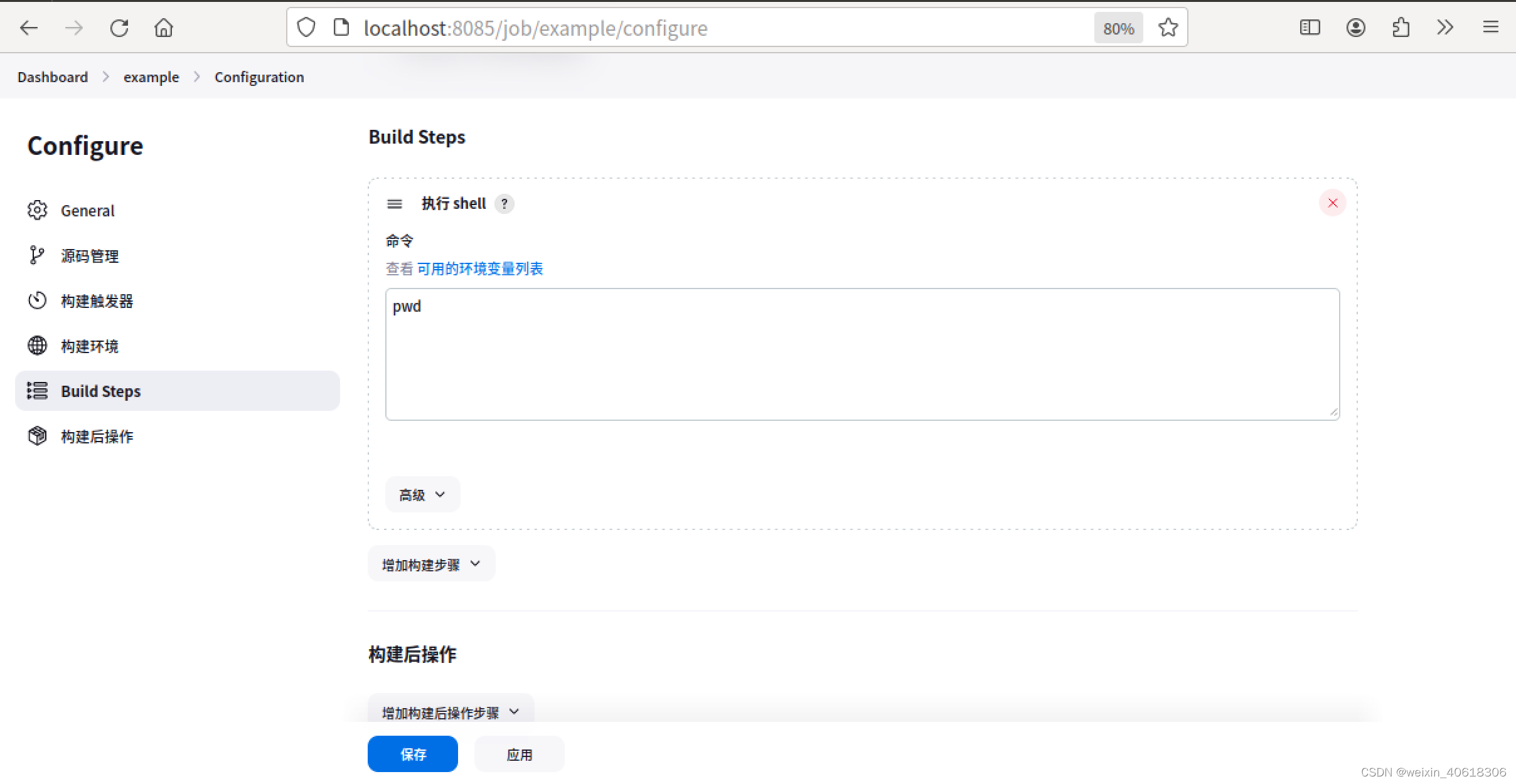
Jenkins的安装和部署
文章目录 概述Jenkins部署项目的流程jenkins的安装启动创建容器进入容器浏览器访问8085端口 Jenkins创建项目创建example项目 概述 Jenkins:是一个开源的、提供友好操作界面的持续集成(CLI)工具,主要用于持续、自动构建的一些定时…
最新文章
- 使用通义千问,为汽车软件需求生成测试用例
- SpringBoot3 + SpringSecurity6 + JWT
- SPRINGBOOT+VUE项目实战
- Golang | Leetcode Golang题解之第61题旋转链表
- 分布式与一致性协议之Raft算法与一致哈希算法(一)
- 第八篇:隔离即力量:Python虚拟环境的终极指南
- 深入理解多层感知机MLP
- 【PPT设计】颜色对比、渐变填充、简化框线、放大镜效果、渐变形状配图、线条的使用
- 设计模式-备忘录模式(Memento Pattern)结构|原理|优缺点|场景|示例
- mxnet gluon GRU 文档
- 深入理解Java消息中间件-新兴的消息中间件技术和工具
- 在控制台实现贪吃蛇
- css代码的定位及浮动
- Linux的vim下制作进度条
- Electron打包流程
- Copilot Workspace是GitHub对人工智能驱动的软件工程的诠释
- 联想小新PRO16 ARM-7换固态硬盘和装双系统win11和ubuntu2022.04
- Unity Android(十) 适配Android14系统
- yolov5-pytorch-Ultralytics训练+预测+报错处理记录
- 基于YOLOv8的水稻虫害识别系统,加入BiLevelRoutingAttention注意力进行创新优化
- PYTHON数据结构-双端队列[deque]-具有队列和栈的特性
- pyqt标签常用qss格式设置
- [信息收集]-端口扫描--Nmap
- 怎么证明E[E(X|Y,Z)Y]= E(X|Y)
- 【项目实战】犬只牵绳智能识别:源码详细解读与部署步骤
- curses --- 终端字符单元显示的处理
- LeetCode解法汇总1038. 从二叉搜索树到更大和树
- LeetCode解法汇总232. 用栈实现队列
- 水经微图Web1.5.0版即将上线
- # 从浅入深 学习 SpringCloud 微服务架构(二)模拟微服务环境(1)